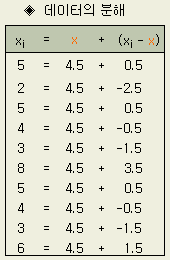 표의
좌변의 제곱합계는 목표값으로부터의 편차의 제곱합이며, 목표값으로부터의 산포의
크기가 된다.
표의
좌변의 제곱합계는 목표값으로부터의 편차의 제곱합이며, 목표값으로부터의 산포의
크기가 된다. |
제6편 통계 기초 2장 분산분석 (ANOVA) |
|
|
두께의 규격이 100 ± 5 ㎛인 어떤 물품 10개의 '목표값과의 차이'는 다음과 같다.
5, 5, 2, 4, 3, 8, 5, 4, 3, 6
10개의 데이터가 모두 플러스이므로, 이 조건에서는 목표 두께보다 두꺼운 경향이 있다는 사실을 알 수 있다. 이같은 치우침은 목표로부터의 편차 평균으로 구해진다. 치우침을 x 로 하면 (x bar 를 x로 표기함)
x = ( 5 + 5 + 2 + … + 6) / 10 = 45 / 10 = 4.5
이다.
목표값과의 차이 xi 는 치우침 ( x ) 와 치우침으로부터의 편차 ( xi - x ) 로 분해할 수 있다. 10 개의 데이터를 치우침 x 와 편차 xi - x 로 분해한 것이 다음의 표이다. 치우침으로부터의 편차 xi - x 는 하나 하나의 차이이므로 個體差라고도 한다.
표의
좌변의 제곱합계는 목표값으로부터의 편차의 제곱합이며, 목표값으로부터의 산포의
크기가 된다.
◈ 변동의 계산
산포의 총량을 전변동이라고 하며, 기호 ST 로 나타낸다
실제로 계산하면
ST = 52 + 52 + 22 + … + 62 = 229 (φ = 10) (※)
이다.
표에서,
우변의 제1항 (값 4.5) 은 치우침이므로 그 제곱의 합계는 치우침의 크기의 총량이다.
다루고 있는 데이터의 평균 크기이므로 일반평균이라고
하며 기호로는 Sm 으로 나타낸다
Sm = 4.52 + 4.52 + 4.52 + … + 4.52
= x2 × 10 = ( 합계 / 10 )2 × 10 = ( 합계 )2 /10 (※)
= 452 / 10 = 202.5 (φ = 1)
표에서, 우변 제2항의 제곱합계는 개별값과 평균적인 치우침과의 차이, 즉 개체차의 제곱합으로 오차변동 이라고 하며 Se 로 나타낸다.
Se = 0.52 + 0.52 + (- 2.5)2 + … + 1.52 = 26.5 (φ = 9)
실제로는 Se 를 다음의 식으로 구한다.
Se = ( x1 - x )2 + ( x2 - x )2 + … + ( x10 - x )2
= ( x12 - 2 x1 x + x2 ) + ( x22 - 2 x2 x + x2 ) + … + ( x102 - 2 x10 x + x2 )
= x12 + x22 + … + x102 - 2 x ( x1 + x2 + … + x10 ) + 10 x2
= x12 + x22 + … + x102 - 2 ( x1 + … + x10 )2 / 10 + 10 { ( x1 + x2 + … + x10 )2 / 102 }
= x12 + x22 + … + x102 - ( x1 + x2 + … + x10 )2 / 10
=
∑ xi2 - ( ∑ xi )2
/ n
=
ST - Sm (※)
그러므로
Se = 229 - 202.5 = 26.5
각
식의 뒤에 부기된 φ 는 각 변동의
자유도이다.
이상에서 변동과 자유도에 관해
ST = Sm + Se
φT = φm + φe
라는 분해가 성립한다. 위의 식을 변동(제곱합)의 분해라고 한다.
|
ST
Sm Se 의
이해 |
|
아래 세가지 데이터는 두째 행의 '기준' 에서 각각 +10, -4.5
를 한 것으로 평균의 수준은 다르지만, 산포는 같은 것이다. Se
= ST
- Sm 의
식에서 각항의 (특히 Sm ) 의미하는 바를 이해하자.
|
어느
제조 공정에서는 4대의 기계로 부품을 가공하고 있다. 기계별로 가공한
3개의 부품의 치수는 다음과 같다. 기계간에 치수의 차이가 있는가를 검토하고자
한다.
데이터의 변화에 영향을 주고 있을 것으로 생각하는 원인을 인자
(factor) 혹은 요인 (source)이라 한다. 또한 어떤 인자에 대해 조건을 수준 (level)이라
한다. 여기서는 기계별이라는 하나의 인자를 다루고 있는 경우라서 一元배치로
4수준의 경우이다.
(3 수준 이상의 평균치의 차의 검정은 정규분포나
t 분포로는 할 수 없다 )
|
기계 |
A1 |
A2 |
A3 |
A4 |
계 |
|
|
87 |
93 |
86 |
85 |
|
|
|
86 |
90 |
85 |
86 |
|
|
|
91 |
89 |
88 |
84 |
|
|
평 균 |
88.0 |
90.7 |
86.3 |
85.0 |
87.5 |
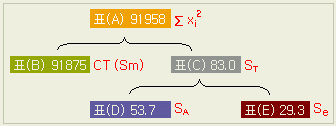
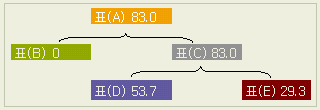
이 데이터를 아래의 표와 같이 분해할 수가 있다.
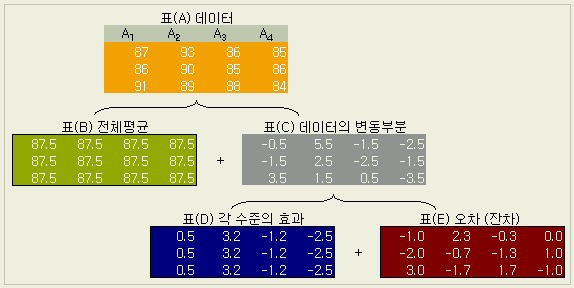
표(D)의 네개의 각 열은 전체평균과 각 열 평균과의 차를 의미한다. 열의 평균값 (0.5, 3.2, -1.2, -2.5 )들이 서로 비슷하냐 아니냐에 따라, 수준 간에 '차이가 없다' 또는 '있다' 라는 판정의 방향이다 ( 바로 '판정한다'고 하지않음은 그 기준이 되는 오차의 변동을 고려해야 하기 때문이다 )
각 표의 데이터를 제곱의 합으로 계산하면 아래와 같이 된다. 각각의 값들이 위의 표와 같은 형태로 분해되고 있음을 보라.
|
|
|
즉
표(A) = 표(B) + 표(C)
표(C)
= 표(D) + 표(E)
이 구조를 다음과 같이 정리할 수 있다.
총변동(ST)
= 群間 변동(SA) + 群內 변동(Se)
=
요인 효과(SA) + 실험 오차(Se)
즉
실험 오차(Se) =
총변동(ST) - 요인 효과(SA)
|
엑셀에 의한 계산 |
|
|
|
주 : '=sumsq(데이터범위)' 는 산술적 의미로서 각 수의 제곱의 합을 구한다 (위의 범위로 확인) |
|
|
A1 |
A2 |
A3 |
A4 |
계 |
|
|
87 |
93 |
86 |
85 |
|
|
|
86 |
90 |
85 |
86 |
|
|
|
91 |
89 |
88 |
84 |
|
|
합 계 |
264 (T1) |
272 (T2) |
259 (T3) |
255 (T4) |
1050 |
|
평 균 |
88.0 (A1) |
90.7 (A2) |
86.3 (A3) |
85.0 (A4) |
87.5 |
(※ 앞으로는 일반변동( Sm )의 값을 수정항 (CT) 으로 표기한다.)
각
변동의 실제계산은 다음과 같다. 즉 CT, ST, SA (다른
인자 B, C, … 가 있을 때는 SB, SC, … 등이 계산됨은 물론이다)를
계산한 다음, Se = ST
- ( SA + SB + SC + … ) 으로
계산한다.
◈ 수정항을 계산한다.
CT
= ( ∑ ∑ xi j )2 / n
=
( 1050 )2 / 12 = 91875
◈ 총변동을 계산한다.
ST
= ∑ ∑ xi j 2 - CT
=
{ 872 + 862 + … + 842 } - CT = 83
◈ 군간변동을
계산한다.
SA
= 3 ( A1
- 87.5 )2 + 3 ( A2
- 87.5 )2 + 3 ( A3
- 87.5 )2 + 3 ( A4-87.5
)2 (정의에 따른 식) =
Σ (
Ti2 / m ) - CT ( 반복수 m가 모두 같을
때 : Σ (
Ti2 ) / m - CT ) (※)
= ( 2642 +
2722 + 2592 + 2552 ) / 3 - CT
=
53.7
◈ 잔차(오차)변동을
계산한다.
Se
= ST - SA
=
83 - 53.7 = 29.3
우리는
앞 장 '통계 입문' 의 검정에서 오차의 변동이 판정의 기준으로 작용함을 알고 있다.
이제 이런 해석을 변동(제곱합) 혹은 분산으로 나타내어본다.
지금까지는 변동(제곱합 sum of square)을 계산하였다. 그러나 변동은 합계적 개념이므로 비교를 위해서는 평균이 필요하다. 따라서 변동의 평균인 분산 ( 변동 / 자유도 )을 사용한다.
◈
수정항 CT 는 합계의 제곱을 데이터
수로 나누어 구하는데 , 하나의 평균값만 알면 구해지는 변동이므로 φCT =
1 이다.
(식의 原形은 평균의 제곱을 데이터수로 곱한 것이나 다음과 같이
변형된다
CT
= ( 평균 )2 × n = ( 합계/n )2 × n = ( 합계
)2 / n.
이 식에서 제곱이 하나임을 주목하자.
즉 자유도는 1 이다 )
◈ 총변동 ST 는 모든 데이터의 제곱에서 CT를 뺌으로 φT = ( 12 - 1) 즉 φT = 11 이다.
◈
군간(요인효과 )변동 SA
는 각 수준의 평균치 (0.5,
3.2, -1.2, -2.5 ) 4개를 알아야 하나, 수준 전체의 합은 0 ( = 0.5 + 3.2 -
1.2 - 2.5 ) 이라는 제약이 있다. 따라서 φA
= 3 이다. 요인효과의 자유도는 (수준수
- 1) 이 된다.
◈
오차변동 Se 는
네개의 각 열의 '평균값으로 부터
개체차' 이므로 각 열당 자유도는 2 가 된다. 따라서 2 × 4열 = 8 이 된다.
(실제 계산에서는 다음에서와 같이 φe=
φT - φA 의
식을 이용)
자유도도
변동의 분해와 같이
ST
= SA + Se 83
= 53.7 + 29.3
φT
= φA + φe 11
= 3 + 8
따라서 분산은 각 변동을 그 자유도로 나눈 값이며, 다음과 같이 정리한 것을 분산분석표라 한다.
|
요 인 |
변동(S) |
자유도(φ) |
분산 (V) |
분산의 기대값 E(V) |
F0 |
F(0.05) |
F(0.01) |
|
요인효과 (A) |
53.7 |
3 |
17.9 |
σe2 + m σA2 |
4.88 * |
4.07 |
7.59 |
|
오차 (e) |
29.3 |
8 |
3.7 |
σe2 |
|
|
|
|
전체 (T) |
83.0 |
11 |
|
|
|
|
|
분산분석도
검정의 한 방법이다. 1원배치에서는 인자 A의 각 수준간의 특성치의 차이가 유의한가를
알아보는 것으로, 각 수준에서의 주효과를 ai
( i = 1, 2, … ) 라 할 때, " 수준간에 특성치의 차이가 없다
" 라는 귀무가설과 이에 대한 대립가설은
귀무가설
H0 : a1
= a2
= a3
= a4
= 0
대립가설
H1 : ai 는 모두 0 은 아니다.
이다. 달리 표현하면
H0
: σA2 = 0 (A 인자의 수준간 분산은 0 이다)
H1 : σA2 > 0 (수준간에 차가
있다 즉 A 인자의 효과)
위의
귀무가설이 성립할 경우, 분산분석표에서 요인효과 (A) 의 기대값 ( σe2
+ m σA2 ) 에서 제2항이 0 이 된다. 따라서
이 때는 VA , Ve 가 같으므로 F분포를 하게 된다. (
분산의 기대값에서 항상 VA 가 Ve보다 작지는 않음을 알 수
있다. 그러므로 분산분석에서는 항상 한쪽검정을 하게된다 )
F0
를 F ( φA , φe : α ) 의 값 (즉 자유도 φA
, φe 유의수준 α 의 F표의 값) 과 비교하여
F0
≥ F ( φA , φe : α ) 이면 유의수준 α로 유의하다
(즉 A 의 수준에 따라 데이터에 차가 있다)
F0
< F ( φA , φe : α ) 이면 유의수준 α로 유의하지않다
고
결론을 내린다.
위의 분산분석에서는
F0
= 군간분산 / 오차분산
=
VA / Ve
=
17.9 / 3.7 = 4.88
분자의 자유도 3, 분모의 자유도 8 에서 한쪽 5 %와 1 %의
확률에 해당하는 임계치는
F
( 3 , 8 : 0.05 ) = 4.07 F ( 3
, 8 : 0.01 ) = 7.59
이다.
따라서 F0
> F ( 3 , 8 : 0.05 ) 이므로 귀무가설은 기각되고, 대립가설을 채택하게
된다. 즉 '위험율 (유의수준 ) 5 %로 기계간에는 차가 있다' 라는 것이 분산분석의
결론이다.
|
특수자기의
개발에서 금속부품접착제의 종류가 접착강도에 미치는 영향을 검토한다.
접착제의 A1'
A2'
A3
의 3종류를 선정해,
각각 4회의 접착실험을 랜덤으로 실험하고, 접착강도를 측정했다.
접착제의 종류에 따라 접착강도가 다른가를 검토하고, 각 접착제의
접착강도의 모평균을 신뢰도 95 % 로 추정한다.
단, A1의 제4회째 데이터 (23) 가 이상하게 작으므로 해석에서는 제외하는 것으로 한다 |
수치변환 ( x - 40 ) 을 한 보조표를 만든다.
|
A1 |
A2 |
A3 |
계 |
|
|
-2 |
5 |
2 |
|
|
|
1 |
3 |
4 |
|
|
|
-5 |
4 |
2 |
|
|
|
|
8 |
3 |
|
|
|
합 계 |
-6 (T1) |
20 (T2) |
11 (T3) |
25 |
|
수치변환(계산의 편의를 위한) |
|
대부분의
통계서적에서 변동등을 계산할 때 수치변환을 하고 있다. 컴퓨터가
없는 시절이었고 또한 한정된 지면에 많은 자리수를 나타내는
불편함때문이었다. 컴퓨터을 사용하는 이제는 그리 심각하지 않게
되었다. 초심자는 헷갈릴 우려가 있으므로 사용을 피하는게 미덥다. |
분산분석의
순서
◈ 수정항을 계산한다.
CT
= ( ∑ ∑ xi j )2 / n
=
( 25 )2 / 11 = 56.82
◈ 총 제곱의 합을 계산한다.
ST
= ∑ ∑ xi j 2 - CT (앞 장에서)
=
{ (-2)2 + 12 + … + 32 } - CT = 120.18
◈ 군간제곱의
합을 구한다.
SA
= Σ ( Ti2
/ m ) - CT
=
(-6)2 / 3 + 202 / 4 + 112 / 4 - CT
=
85.43
◈ 잔차(오차)제곱의
합을 구한다.
Se
= ST - SA
=
120.18 - 85.43 = 34.75
◈ 자유도는 다음과 같다.
전
자유도 φT = (데이터의
총수) - 1 = 11 - 1 = 10
A
의 자유도 φA = (A 의 수준수 ) - 1 = 3 -
1 = 2
잔차
자유도 φe = φT - φA
= 10 - 2 = 8
|
요 인 |
변동(S) |
자유도(φ) |
분산 (V) |
F0 |
F(0.05) |
F(0.01) |
|
요인효과 (A) |
85.43 |
2 |
42.72 |
9.84 ** |
4.46 |
8.65 |
|
오차 (e) |
34.75 |
8 |
4.34 |
|
|
|
|
전체 (T) |
120.18 |
10 |
|
|
|
|
◈
결론 : 접착제의 종류에 의한 효과는 유의수준 1 % 로 유의하다.
수준의
모평균의 추정
각 수준에서 접착강도의
모평균의 점추정값은
μ1 =
38.0 (kg) μ2
= 45.0 (kg) μ3
= 42.8 (kg)
(1-α)×100 % 신뢰한계 :
μ
± t (φ, α) × ( √
Ve / √ ni
)
=
μ
± t (φ, α) × √
( Ve / ni )
◎ μ1 의
95 % 신뢰한계 : 38.0 ± t (8, 0.05) √
(4.34 / 3)
=
38.0 ± 2.306 × 1.20 = 38.0 ± 2.8
=
40.8, 35.2
◎ μ2 의
95 % 신뢰한계 : 45.0 ± t (8, 0.05) √
(4.34 / 4)
=
45.0 ± 2.306 × 1.04 = 45.0 ± 2.4
=
47.4, 42.6
◎ μ3 의
95 % 신뢰한계 : 42.8 ± t (8, 0.05) √
(4.34 / 4)
=
42.8 ± 2.306 × 1.04 = 42.8 ± 2.4
=
45.2, 40.4
일원배치는 문제가 되는 인자를 하나만 취하여, 몇가지 수준으로 실험을 하며, 인자로 취급하지 않는 여러조건은 일정하게 하고, 실험의 순서를 랜덤하게 정하여 실시한다.
2원배치는 두개의 인자를 취하여 실험하는 것이다. 각 조건에서 반복이 있는 경우도 있지만, 반복이 없는 즉 각 조건에서 한번 씩 실험한 경우를 보자. 이 때도 실험전체를 완전 랜덤화함이 원칙이다 (아래의 20종 실험을 완전히 랜덤한 순서로 하는 것).
2원배치법에는
모수모형과 혼합모형이 있는데, 두 인자가 모두 모수인자인 경우가 전자이며, 두
인자중 하나가 변량인자인 경우가 후자이다.
(모수인자는 그 수준을 지정하여
조업을 할 수 있는 경우이며, 변량인자는 그 수준을 고정하여 적용할 수 없는 경우이다.
전자에는 처리온도, 시간, 원료의 종류등이 그것이며, 후자에는 날에 따른 차이,
입하된 드럼별의 차이 등인데, 이들은 현상을 파악하거나, 실험의 정도를 높이기
위한 수단으로 사용될 수 있다)
여기서는
모수모형의 경우를 본다.
|
합금의
경도에 영향을 미치는 처리온도 (A) 와 망간 함량 (B)의 실험
|
◈
수정항을 계산한다.
CT
= ( 998)2 / 20 = 49800.2
◈ 총 제곱합을 계산한다.
ST
= ∑ ∑ xi j 2 - CT
=
{ 502 + 482 + … + 492 } - CT
=
165.8
◈ 행간 제곱의 합을 계산
SA
= Σ ( Ti2
) / m - CT )
=
(2622 + 2512 + 2512 + 2342 ) / 5
- CT
=
249402 / 5 - CT
=
80.2
◈ 열간 제곱의 합을 계산
SB
= Σ ( Tj2
) / m - CT )
=
(1912 + 1942 + 2022 + 2032 + 2082)
/ 4 - CT
=
199394 / 4 - CT
=
48.3
◈ 오차(잔차)제곱의 합을 계산
Se
= ST - SA - SB
=
165.8 - 80.2 - 48.3 = 37.3
◈ 자유도의 계산
전 자유도
(φT)는 수정항 (CT) 의 자유도 1 을 뺀 n - 1 = 19 이다.
인자의
자유도 : (수준수 - 1) 따라서 φA = (4 - 1) φB
= (5 - 1) .
잔차의
자유도 : φe = φT - (φA + φB
) = 19 - 7 = 12
◈ 분산분석표
|
요 인 |
변동 (S) |
자유도(φ) |
분산 (V) |
F0 |
F (0.05) |
F (0.01) |
|
처리온도 (A) |
80.2 |
3 |
26.7 |
8.59 ** |
3.49 |
5.95 |
|
망간함량 (B) |
48.3 |
4 |
12.1 |
3.89 * |
3.26 |
5.41 |
|
잔차 (e) |
37.3 |
12 |
3.11 |
|
|
|
|
전체 (T) |
165.8 |
19 |
|
|
|
|
◈
결론
온도의 영향은 유의수준 1
%로 수준간에 유의차가 있다.
망간함량의
영향은 유의수준 5 %로 수준간에 유의차가 있다.
2.7
엑셀에 의한 계산
엑셀의
메뉴
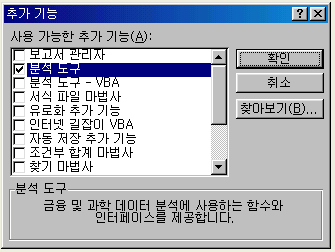
엑셀의 주메뉴에서 <도구> <데이터
분석>을 선택한다.
만약 <데이터 분석>이 없는 경우는 <도구> <추가기능>을 선택하면 다음의 화면이 나타난다. <분석도구>의 앞 첵크란에 첵크를 하고 <확인> tab을 누르면 <데이터 분석>이 설치된다. 이렇게 해서 나타나지 않는 경우는 Microsoft Office의 CD를 사용하여 보완설치를 해야 한다.
<데이터
분석>이 선택하면 다음의 화면이 나타난다. 여기서 해당항목을 선택한다.
분산분석의
경우, 세가지가 나타나는 데 지금은 '반복없는 2원 배치법'을 선택해야 한다.
'반복없는
2원 배치법' 에서 선택하는 화면은 아래와 같다.
① 입력범위 : 마우스의
커서가 입력범위의 입력란에 두고 (혹은 오른쪽 빨간색 아이콘을 클릭해서), 데이터가
있는 셀의 범위를 마우스로 표시한다. 이 때 인자와 수준(A1, A2, … B5 들)을
결과표에 사용하기 위하여 그 이름이 있는 셀까지 범위로 지정하고, 아래의 '이름표'
앞에 체크를 한다.
② 유의수준 : default 로 설정된 0.05 를 그냥두면 된다 (0.01을 입력할 필요가 없음을 다음에서 설명)
③
출력옵션
⊙
출력범위 : 현재의 워크시트에 결과를 출력하고자 할 때, 출력표의 좌상의 한 셀을
mouse로 클릭함으로써 입력된다 (이것을 선택함이 original data 와 비교함에 편리할
것이다) 아래 그림은 입력한 결과.
⊙
새로운 워크시트 : 말 그대로 현재의 시트옆에 새 시트가 추가되고, 결과가 출력된다.
⊙ 새로운 통합문서 : 통합문서(Workbook)는 시트의
상위개념이다.
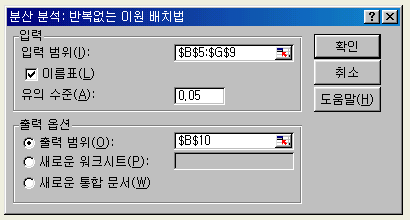
실험결과의 original data
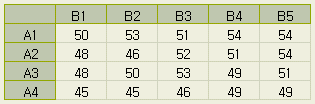
엑셀에
의한 계산결과의 출력표 (
데이터의 소숫점 아래 자리는 정리한 것임 )
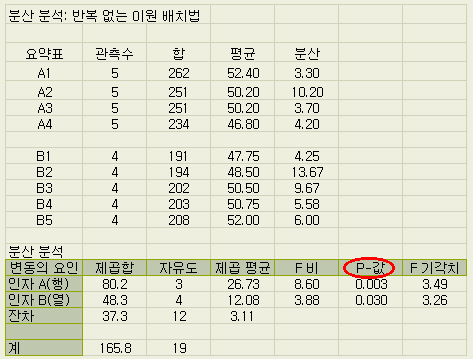
위에서의
손 계산과 다른 부분만을 설명하면.
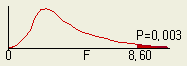 ◈
P-값 : F분포에서 F비의 오른쪽 누적확률(Probability)의 값을 표시. 인자 A 의 F비가
8.60 일 때, 이 오른쪽의 누적확률은 0.003 (0.3 %)임을 나타낸다.
◈
P-값 : F분포에서 F비의 오른쪽 누적확률(Probability)의 값을 표시. 인자 A 의 F비가
8.60 일 때, 이 오른쪽의 누적확률은 0.003 (0.3 %)임을 나타낸다.
이
값이 0.05 이하이면 유의수준 5 %로 유의, 0.01 이하이면 유의수준 1 %로 유의함을
알 수 있다.
(이 값이 있음으로 조건설정에서 유의수준은 default값 : 0.05 로
고정시켜도 지장없음을 알 수 있다. 즉 0.01로 바꾸어 1 %에서도 유의한지 아닌지를
확인할 필요가 없다는 것)
◈ F기각치
: 계산의 조건에서 설정한 유의수준에 해당하는 F의 임계치.
인자 A 의 경우,
유의수준에서 지정한 오른 쪽 누적확률 0.05 에 해당하는 F0 (엑셀에서는
F비)가 3.49 임을 나타낸다.
※
엑셀의 <데이터 분석>으로 2원배치까지의 계산은 그야말로 '식은 죽 먹기'
가 된다. <데이터 분석>에 있는 다른 해법도 대부분 그러하다. 가능한 메뉴들은
다음과 같다 (Excel 2000 ). 
2원배치법과
동일한 조건에서, 2회이상 데이터가 있는 것을 반복있는 2원배치법이라 한다.
|
합금의
표면처리를 함으로써 내산성(耐酸性)이 증가하는지 어떤지를 알고
싶다. 합금중에 포함된 크롬함량을 달리해서 다음과 같은 데이터를
얻었다.
|
◈
수정항을 구한다.
CT
= 2.412 / 24 = 0.242
◈ 총제곱의
합을 구한다.(원표에서)
ST
= 0.122
+ 0.132
+ …
+ 0.112
- CT = 0.0089
◈ 군간제곱의
합을 구한다. (보조표에서)
SRC
= (0.362
+ 0.342
+ 0.292
+ …
+ 0.302)
/ 3 - CT = 0.00716
◈ 행간
제곱의 합을 구한다. (보조표에서)
SR
= (1.102
+ 1.312)
/ 12 - CT = 0.00184
◈ 열간
제곱의 합을 구한다. (보조표에서)
SC
= (0.702
+ 0.652
+ 0.562
+ 0.502)
/ 6 - CT = 0.00401
◈ 교호작용
제곱의 합을 구한다.
SR×C
= SRC - (SR + SC) = 0.00716 - (0.00184
+ 0.00401)= 0.00131
◈ 잔차(오차)제곱의
합을 구한다.
Se
= ST - SRC = 0.0089 - 0.00716 = 0.00174
◈
이상의
결과를 정리해서 분산분석표를 만들어 검정한다.
|
요 인 |
변동 (S) |
자유도(φ) |
분산 (V) |
F0 |
F (0.05) |
F (0.01) |
|
표면처리 |
0.00184 |
1 |
0.00184 |
16.9 ** |
4.49 |
8.53 |
|
크롬함량 |
0.00401 |
3 |
0.00134 |
12.3 ** |
3.24 |
5.29 |
|
교호작용 |
0.00131 |
3 |
0.00044 |
4.0 * |
3.24 |
5.29 |
|
잔차 (e) |
0.00174 |
16 |
0.000109 |
|
|
|
|
전체 (T) |
0.00890 |
23 |
|
|
|
|
F
분포표를 검정하면 표먼처리여부, 크롬함량간에는 고도로 유의(**)하고, 두 인자간의
교호작용도 유의(*)하다.
반복실험의
효과
위 실험결과를 '반복없는' 2원배치로
할 경우 어떻게 되는가를 본다. 앞의 분산분석표와 대비하라.
( 3회 반복의
평균치를 데이터로 사용한다)
|
|
크롬 1% |
크롬 2% |
크롬 3% |
크롬 4% |
|
표면처리 |
0.120 |
0.097 |
0.083 |
0.067 |
|
不 처리 |
0.113 |
0.120 |
0.103 |
0.100 |
|
요 인 |
변동 (S) |
자유도(φ) |
분산 (V) |
F0 |
F (0.05) |
F (0.01) |
|
표면처리 |
0.00061 |
1 |
0.00061 |
4.2 |
10.1 |
34.1 |
|
크롬함량 |
0.00134 |
3 |
0.00045 |
3.1 |
9.3 |
29.5 |
|
잔차 (e) |
0.00044 |
3 |
0.00015 |
|
|
|
|
전체 (T) |
0.00239 |
7 |
|
|
|
|
◈
결과에서의 차이점
① 3회 반복있는 데이터에서 '고도로 유의 (**)' 한
표면처리, 크롬 함량이 반복없는 1회의 실험에서는 유의로 되지 않았다. (즉 검출력이
낮다. 검출력이란 귀무가설을 기각할 수 있는 즉 대립가설을 채택할 수 있는 능력이다.
실제로 차이가 있음에도 데이터가 적어 (데이터의 신뢰성이 낮아) 우리는 차이가
있다는 판정을 내릴 수 없다). 잔차의 자유도가 작기 때문이다. 잔차의 자유도는
실험회수에 의한다.
② 교호작용을 검출할 수 없다 (교호작용은 잔차와 교락되어있다)
|
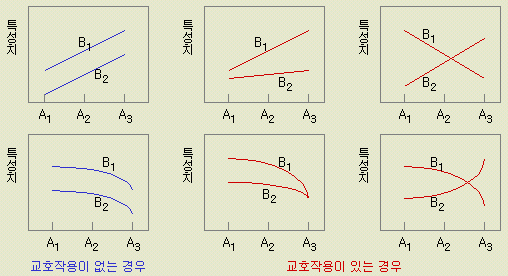
교호작용 (interaction) |
|
만약
교호작용이 없다고 한다면 모든 실험은 매우 쉽게 된다.
즉 한 인자씩 실험해서 각 인자의 최적 수준을 찾고, 그들을 조합하기만
하면 전체의 최적이 되기 때문이다.
그러나 실제로는 인자간에 있을 교호작용때문에 모든 조합의 실험을
해야 한다. 그런데 모든 조합의 실험회수란 예를 들어 3수준의 경우 |
2원배치에 있어서 동일조건으로 반복 실험이 되거나, 3원 이상의 배치법의 실험에서는 교호작용을 검출할 수 있다. 2원배치에서 반복이 없으면 교호작용을 검출할 수 없다. 이 때 교호작용의 효과는 오차에 포함되어 버린다 ( 통계용어로서 어떤 효과가 다른 것과 섞이는 것을 교락(交絡)이라고 한다)
|
흡습제를 사용에서 ① 흡습제 메이커 ② 품종 ③ 전처리 여부 등의 3개인자를 선택하여 다음과 같은 데이터를 얻었다.
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
이
경우에는 인자가 3 이므로 2인자 교호작용을 검출할 수 있다. 따라서 요인으로서는
A, B, C, A×B,
B×C,
C×A,
e(오차)를 생각하여야 하며 이 계획이 3원배치이다.
◈
수정항을 구한다.
CT
= 3562 / 12 = 10561.3
◈ 총제곱의
합을 구한다.(원표에서)
ST
= 272
+ 302
+ …
+ 352
- CT = 172.7
◈ 회사간 제곱의 합을 구한다.
SA
= (1182 + 1102 + 1282) / 4 - CT =
40.7
◈ 품종간 제곱의 합을 구한다.
SB
= (1632 + 1932) / 6 - CT = 75.0
◈ 전처리 실시여부간의
제곱의 합을 구한다.
SC
= {(80 + 92)2 + (83 + 101)2} / 6 - CT =
12.0
◈ A와 B의 조합에 의한 군간 제곱의 합을 구하여 이로부터 A와 B의 교호작용
제곱의 합을 구한다.
SA
B = {(A1B1의 조합계)2 + (A1B2의
조합계)2 + … + (A3B2의 조합계)2}
/ 데이터수 - CT
=
{(27 + 30)2 + (29 + 32)2 + (23 + 22)2
+ … + (32 + 35)2} / 2 - CT = 153.7
SA×B
= SA
B - (SA
+ SB)
= 153.7 - (40.7 + 75.0) = 38.0
◈ B와 C의 조합에 의한 군간제곱의 합을
구하고 이로부터 B와 C의 교호작용의 제곱의 합을 구한다.
SBC
= (802 + 832 + 922 + 1012)
/ 3 - CT = 90.0
SB×C
= SBC
- (SB
+ SC)
= 90 - (75.0 + 12.0) = 3.0
◈ C와 A의 조합에 의한 군간제곱의 합을 구하고
이로부터 C와 A의 교호작용의 제곱의 합을 구한다.
SCA
= ((27 + 29)2 + (23 + 31)2 + (30 + 32)2
+ … + (31 + 35)2) / 2 - CT = 54.7
SC×A
= SCA
- (SC
+ SA)
= 54.7 - (12.0 + 40.7) = 2.0
◈ 잔차(오차) 제곱의 합을 구한다
Se
= ST
- (SA
+ SB
+ SC
+ SA×B
+ SB×C
+ SC×A
) = 2.0
◈ 이상의 결과를 정리해서 분산분석표를 만든다. 교호작용의
자유도는 그 인자의 자유도의 곱과 같다.
|
요 인 |
변동 (S) |
자유도(φ) |
분산 (V) |
F0 |
F (0.05) |
F (0.01) |
|
회사 (A) |
40.7 |
2 |
20.4 |
20.4 * |
19.0 |
99.0 |
|
품종 (B) |
75.0 |
1 |
75.0 |
75.0 * |
18.5 |
98.5 |
|
처리 (C) |
12.0 |
1 |
12.0 |
12.0 |
18.5 |
98.5 |
|
교호작용 (A×B) |
38.0 |
2 |
19.0 |
19.0 * |
19.0 |
99.0 |
|
(B×C) |
3.0 |
1 |
3.0 |
3.0 |
18.5 |
98.5 |
|
(C×A) |
2.0 |
2 |
1.0 |
1.0 |
19.0 |
99.0 |
|
잔차 (e) |
2.0 |
2 |
1.0 |
|
|
|
|
전체 (T) |
172.7 |
11 |
|
|
|
|
◈
분산비의 값과 분포표의 값을 비교하여 판정을 한다.
이 예에서는 회사간, 품종간, 처리간의 차이를 인정할 수 있다. 또 회사와 품종간에 교호작용이 있어 회사에 따라 품종의 차가 고르지 않음을 알 수 있다.
이
예에서는 B×C, C×A 의 교호작용은 유의가 아닐 뿐 아니라 그 분산은
잔차분산에 비해서 그리 크지 않다. 이런 경우에는 이들의 교호작용은 없는 것으로
간주하고 이들을 잔차항에 포함시키는 것을 풀링(pooling)이라 한다. 풀링한 잔차에
의해 계산한 아래의 분산분석표를 본래의 그것과 비교해 보라. 잔차항의 자유도가
클수록 검출력이 커지기 때문이다.
|
요 인 |
변동 (S) |
자유도(φ) |
분산 (V) |
F0 |
F (0.05) |
F (0.01) |
|
회사 (A) |
40.7 |
2 |
20.4 |
14.6 ** |
5.79 |
13.3 |
|
품종 (B) |
75.0 |
1 |
75.0 |
53.6 ** |
6.61 |
16.3 |
|
처리 (C) |
12.0 |
1 |
12.0 |
8.6 * |
6.61 |
16.3 |
|
교호작용 (A×B) |
38.0 |
2 |
19.0 |
13.6 ** |
5.79 |
13.3 |
|
풀링잔차 (e') |
7.0 |
5 |
1.4 |
|
|
|
|
전체 (T) |
172.7 |
11 |
|
|
|
|
|
풀링(pooling) |
||||||||||||||||||||||||||
|
분산분석에서
유의하지 않는 교호작용은 오차항에 넣어서 새로운 오차항으로 만드는
것을 풀링이라 한다. 인자의 배치가 많은 직교표를 이용하는 실험에서는
오차의 자유도가 작아서 검출력이 나쁘므로 유의하지 않는 인자도
풀링할 수 있다.
검출력은
유의한 경우, 유의하다고 판정할 수 있는 확률이라 할 수 있다.
자유도가 낮은 경우 (실험회수가 작아서) 검출력이 낮아진다. |
||||||||||||||||||||||||||
분산분석표가 작성되고 검정이 끝난 다음에 어떤 인자를 어떤 수준에서 실험하였을 때의 모평균이나 어떤 조건에서의 모평균을 추정할 필요가 있을 수 있다. 모평균의 추정에 대해서는 이미 [통계 기초]의 장에서과 같이 계산할 수 있다. 모표준편차를 모르는 경우이므로 t 분포를 이용한
x
± t (φ, α) × ( √
V / √
n )
에서 √
V 대신에 √
Ve 를 쓰고 t
(φ, α) 의 자유도를 φe로
하여 계산하면 된다.
|
§ 2.5 2원 배치(반복없는) 의 예제로 실제 계산을 해 본다.
|
각
수준의 모평균의 추정
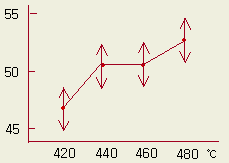
각 온도에서 경도의 모평균을 95 % 신뢰도로 구간추정하면 다음과 같이 된다.
x (A1) = 262/5 = 52.4 x (A2) = 251/5 = 50.2
x (A3) = 251/5 = 50.2 x (A4) = 234/5 = 46.8 (A)
분산분석표에서
 t
(12, 0.05) = 2.18 √
Ve
= √ 3.11 = 1.76
t
(12, 0.05) = 2.18 √
Ve
= √ 3.11 = 1.76
n
= 5 ( 온도의 각 수준에서 )
∴ t (12, 0.05) √
Ve
/ √ n = 1.72 ≒1.7
그러므로
μ (A1)
: 52.4±1.7 = 50.7, 54.1
μ
(A2)
: 50.2±1.7 = 48.5, 51.9
μ
(A3)
: 50.2±1.7 = 48.5, 51.9
μ
(A4)
: 46.8±1.7 = 45.1, 48.5
로 구간추정할
수 있다.
이 결과를 도시하면 오른 쪽과 같다. 망간함량 ( n = 4 임에 유의)
이나, 다른 1원배치의 경우에도 같은 방법으로 추정할 수 있다.
처리조건 AiBj 에서의 추정
다음
각 인자의 조합조건에서의 모평균의 추정, 예를 들면 처리온도 460 ℃와 망간함량
6 % 일 때의 경도를 추정하는 방법이다. 다음의 식으로 구한다. 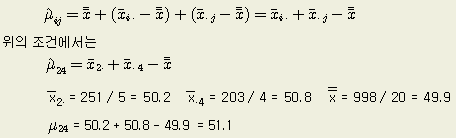
모평균의 신뢰한계는 다음식에서 구한다.
xi j ± t (φ, α) √ ( Ve / √ ne )
여기서
ne는
유효반복수라고 하는 것으로서
ne
= 실험총수 / (오차항에 풀링되지 않는 요인의 자유도의 합 + 1 )
으로
계산된다. 위의 조건에서는
ne
= 20 / ( 3 + 4 + 1 ) = 2.5
95 %의 신뢰한계는
51.1±
t (12, 0.05) × √ ( 3.11 /
2.5 )
=
51.1 ± 2.179 × 1.12
=
48.8 및 53.3
1)
목적이 무엇인지 확실히 하여둘 것
2) 목적에 대하여 취급한 인자가 적당한가.
그 수준의 폭은 적당한가 ( 단, 품질공학의 실험에서는 폭을 가능한 크게 잡는다
)
3) 검정에 의해 수준의 평균을 구하고자 할 때는 오차의 자유도 φe 가
6 ~ 20 정도 되도록 인자와 수준의 수를 정함이 좋다. ( 6 미만에서는 F값이
급격하게 변하여 신뢰도가 낮고, 20 이상에서는 실험회수의 증가에 대비하여 신뢰도의
향상정도가 크지 못하다)
4) 데이터가 어떠한 素性의 것인가를 확실히 해둘 필요가
있다. 뜻하지 않았던 원인이 내재하여 의외로 오차분산이 커지거나 하는 수가 있다.
5)
무엇이 랜덤화되었는지를 주의할 필요가 있다. 랜덤화가 다르면 계산방법이 다른
경우가 있다. 여기서 언급치 않았지만 분할법 등이 있다.
6) 결론을 실험의 범위이상으로
확대하는 것은 조심해야 한다.
예를 들면 100 ~ 120 ℃의 온도범위에서 온도가
유의아님으로 결론이 나왔다면, 그 특성에 온도가 영향을 미치지 않는다는 것이 아니라,
'100 ~ 120 ℃의 변화로는 영향을 미친다고 할 수 없다'는 것이다. 130 ℃로 되면
영향이 있을지도 모른다.
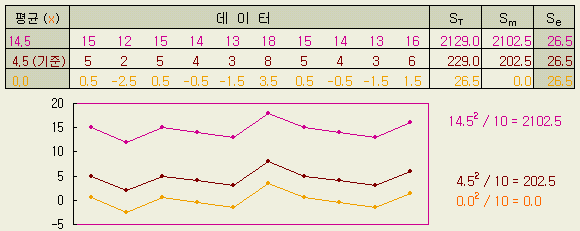
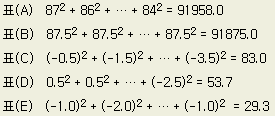
 엑셀
함수 =devsq(데이터범위)
로 위의 표 (A) ~ (E) 를 계산하면 오른쪽의
값을 얻는다.
엑셀
함수 =devsq(데이터범위)
로 위의 표 (A) ~ (E) 를 계산하면 오른쪽의
값을 얻는다.