|
제2편 상론 2장 변동의 해석 |
|
2.1 데이터의 구조 2.2 목표값에 대한 치우침과 변동 2.3 변동의 기대값과 순변동 2.4 분산과 그 기대값 2.5 분산분석 2.6 치우침의 수정과 품질향상 2.7 망목특성의 SN비 2.8 SN비와 감도 2.9 일원배치의 SN비 |
실험결과의 해석을 위해서는 분산분석이란 수법이 사용되며, 이를 위해서 변동(제곱합)의 이해가 필요하다. 이 章은 품질공학강좌 제4권 [품질설계를 위한 실험계획법]에 거의 의지했다.
연구 · 개발이나 기존의 제조조건을 개선하기 위한 실험에서 우리가 확인하고 싶은 것은
① 영향력이 있는 인자는 무엇이며 얼마나 영향을 미치는가? (기여도의 확인)
② 각 인자의 어느 수준이 최적이 될것인가?
③ 최적조건에서 특성치와 (금액)효과는 어떻게 될것인가?
등이며, 이를 위한 실험데이터의 해석수법이 R.A.Fisher(영국 1890 ~ 1962)에 의해 확립된 '분산분석'이다. 제조현장에서는 산포의 척도로서 표준편차를 많이 사용하지만, 분산분석에서는 변동(편차제곱합 )과 분산이 사용된다. 이 장에서는 실험해석의 기초가 되는 변동에 대하여 논의한다. 그 준비운동으로 다음의 데이터를 보자.
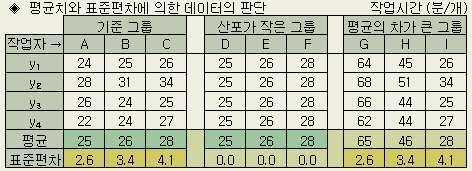
다음은 작업자별로 제품을 만드는데 소요된 시간(분/개)을 측정한 세가지 경우라고 하자. 각 그룹에서 세 작업자별로 기능에 차이가 있다고 볼 수 있는가 ? - 그 판단의 근거는 무엇인가 ?
만약 평균값만 비교하여 '기준그룹' 의 A, B, C 와 '산포가 작은 그룹' 의 D, E, F를 같이 취급한다면 통계적 센스에서 매우 심각한 수준이다. 적어도 다음과 같은 판단은 되어야 할 것이다.
" A, B, C 작업자간에 우열이 있는지는 바로 판단하기가 쉽지 않다. 그러나 D, E, F 간에는 차이가 있다고 단언할 수 있다."
이런 판단에 있어서 '엄밀한 계산'은 모르지만, (평균의 차 / 데이터의 산포) 라는 어렴풋한 수치의 감으로 판정하게 된다. 그런 점에서 G, H, I 간에는 차이가 있다고 해도 좋을 듯 하다. 어중간한(?) 값이 되면 판정이 애매하지만. 실험 해석의 기본이 되는 분산분석도 이런 사고방식에 의하며 이장에서 설명하는 내용이된다.
두께의 규격은 100 ± 5 ㎛으로, 불합격이 되었을 때의 손실 A는 300 원이다. 어떤 조건에서 만든 물품 10개의 '목표값과의 차이'는 다음과 같았다.
5, 5, 2, 4, 3, 8, 5, 4, 3, 6,
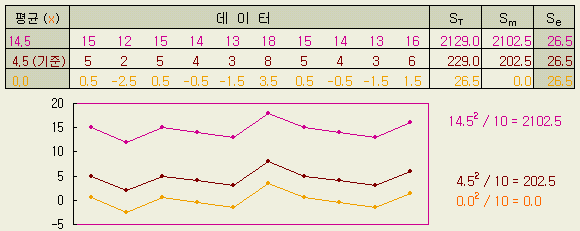
10개의 목표값과의 차이는 모두 플러스이므로, 이 조건에서는 목표 두께보다 두꺼운 경향이 있다는 사실을 알 수 있다. 이같은 치우침은 목표로부터의 편차 평균으로 구해진다. 치우침을 y로 하면 (y bar 를 y로 표기함)
y = ( 5 + 5 + 2 + … + 6) / 10 = 45 / 10 = 4.5
이다.
목표값으로부터의 차이 yi 는 치우침 (y)와 치우침으로부터의 편차 (yi - y)로 분해할 수 있다. 10 개의 데이터를 치우침 y와 편차 yi - y로 분해한 것이 다음의 표이다. 치우침으로부터의 편차 yi - y는 하나 하나의 차이이므로 個體差라고도 한다.
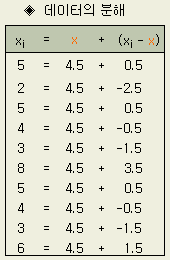 표의
좌변의 제곱합계는 목표값으로부터의 편차의 제곱합이며, 목표값으로부터의 산포의
크기가 된다.
표의
좌변의 제곱합계는 목표값으로부터의 편차의 제곱합이며, 목표값으로부터의 산포의
크기가 된다.
◈ 변동의 계산
산포의 총량을 전변동이라고 하며, 기호 ST 로 나타낸다
( sum of squares : 편차제곱합 혹은 제곱합 으로 부른다)
실제로 계산하면
ST = 52 + 52 + 22 + … + 62 = 229 (f = 10) (※)
이다.
표에서, 우변의 제1항 (값 4.5) 은 치우침이므로 그 제곱의 합계는 치우침의 크기의 총량이다. 다루고 있는 데이터의 평균 크기이므로 일반평균이라고 하며 기호로는 Sm 으로 나타낸다
Sm = 4.52 + 4.52 + 4.52 + … + 4.52
= y2 × 10 = ( 합계 / 10 )2 × 10 = ( 합계 )2 /10 (※)
= 452 / 10 = 202.5 (f = 1)
표에서, 우변 제2항의 제곱합계는 개별값과 평균적인 치우침과의 차이, 즉 개체차의 제곱합으로 오차변동 또는 개체차 변동이라고 하며 Se 로 나타낸다.
Se = 0.52 + 0.52 + (- 2.5)2 + … + 1.52 = 26.5 (f = 9)
실제로는 Se를 다음의 식으로 구한다.
Se = ( y1 - y )2 + ( y2 - y )2 + … + ( y10 - y )2
= ( y12 - 2 y1 y + y2 ) + ( y22 - 2 y2 y + y2 ) + … + ( y102 - 2 y10 y + y2 )
= y12 + y22 + … + y102 - 2 y ( y1 + y2 + … + y10 ) + 10 y2
= y12 + y22 + … + y102 - 2 ( y1 + y2 + … + y10 )2 / 10 + 10 { ( y1 + y2 + … + y10 ) / 10 }2
= y12 + y22 + … + y102 - ( y1 + y2 + … + y10 )2 / 10
= ST - Sm (f = 10 - 1) (※)
그러므로 Se = 229 - 202.5 = 26.5
|
ST
Sm Se 의 이해 |
|
아래 세가지 데이터는
두째 행의 '기준' 에서 각각 +10, -4.5 를 한 것으로 평균의
수준은 다르지만, 산포는 같은 것이다. Se
= ST
- Sm의
식에서 특히 Sm이 의미하는 바를 이해하자.
|
◈
자유도 (degree of freedom)
변동(sum
of squares)은 산포의 합계이므로 평균값으로서의 산포가 필요하게 된다. 어떤 것에
대한 평균인가하면, 자유도에 대해서 구하는 것이다. 위 각식 다음의 괄호 안에 있는
것이 자유도이다.
자유도는
변동 계산에서 미지수의 개수이며, 실질적인 제곱의 개수로써 구할 수 있다. 기호
f 를 사용하며 T, m, e등의 첨자로써 구분 표시한다 ( φ를 사용하기도 한다).
전제곱합
ST 는 모든 데이터가 결정되어야 비로소 계산할 수 있으므로 자유도는
데이터의 개수이다. 즉 fT = 10 이다.
일반평균은
합계의 제곱을 데이터수로 나누어 구하는데, 내용은 평균의 제곱을 데이터 수만큼
곱한것이다. 하나의 평균값만 알면 구해지는 변동이므로 fm=1이다.
오차변동은
10개의 개체차의 제곱합인데, 개체차의 합계가 제로라는 제약식이 한 개 있으므로
개체차에 관한 미지수는 9, 즉 자유도 fe 는 9 이다 (∵ 10 개의
합이 0 일 때 9개의 값은 자유(?)로울 수 있는 변수이지만 나머지 한 개는 고정값이
된다).
이상에서 변동과 자유도에 관해
ST = Sm + Se
fT = fm + fe
라는 분해가 성립한다. 위의 식을 제곱합의 분해라고 한다.
(이 절이 조금 헷갈리는 부분이기도 하다)
앞 절에서 치우침으로 평균값을 사용했다. 이것은 데이터에서 얻어진 추정값이다. 참된 치우침은 실제로는 모르는 것이지만, 목표값으로부터의 차이 y 를 무한 회(回) 취하여 평균하면 참된 치우침 m 이 되는 것으로 생각할 수 있다. 이를
E (y) = m
으로 나타내고,y 의 기대값(expected value)은 m 이라고 한다. 그리고 무한 회(回)의 y 의 분산 σ2 을 V (y)로 표시한다.
V (y) = σ2
이때 y2 의 기대값은 m2 이 아니라, 다음과 같이 된다는 사실이 알려져 있다.
E (y2) = m2 + σ2
(이를 체험적으로 이해하려면 특정한 평균과 분산의 난수를 발생시켜 그 제곱평균이 어떻게 되는지를 검토해 볼 수 있다. 클릭→ 데이터 예시)
윗 식에 의해 k 개의 데이터의 제곱합을 ST 라 하면 그 가운데에는 (m2 + σ2 ) 이 k 개 포함된다.즉 E (ST ) = k ( m2 + σ2 )
로 표시된다.
다음에 k 개 y 의 합의 기대값과 분산은
E ( ∑ y ) = k m
V ( ∑ y ) = k σ2 ( 분산의 加成性에서)
으로 주어진다는 사실이 알려져있으므로 y 의 합계의 제곱은
E ( ∑ y )2 = ( k m )2 + k σ2
이다.
일반평균 Sm 은 (앞 절에서) 평균의 제곱의 k 배이므로 그 기대값 E (Sm)은
E (Sm) = E[ k y2 ]= E[ k { ( ∑y ) / k }2 ] = E[ ( ∑y )2 / k ] = { ( k m )2 + k σ2 } / k
= k m2 + σ2
이 된다. 우변의 제1항은 참된 치우침 m 의 제곱 합계이므로, 이것이 참된 치우침의 크기에 해당된다는 뜻에서 k m2 을 치우침의 순변동이라고하며,prime기호( ' )를 붙여서 표시한다.즉
E (Sm) = Sm' + σ2
단, Sm' = k m2
다음에 오차변동에 대해서는
E (Se) = E ( ST - Sm ) = k (m2 + σ2 ) - ( k m2 + σ2 )
= k σ2 - σ2
으로 우변의 제1항을 오차의 순변동 Se' 라고한다.
E (Se) = Se' - σ2
이상의 사실에서 순변동에 관해서도
ST = Sm' + Se'
가 성립된다고 할 수 있다.
자유도
1개당 변동을 분산(variance)이라고 하며 기호는 V 로 나타낸다 ( 변동이 합계라면
분산은 평균이다). 분산의 제곱근이 표준편차(standard deviation)이며, 산포의
상태를 데이터의 차원으로 표시한 것이다.
전제곱합 ST 의 자유도는 10 이므로 분산 VT 는
VT = ST / fT = 229 / 10 = 22.9
이것은 목표값으로부터의 산포의 평균을 나타낸다.일반평균 Sm 의 자유도는 1 이므로 분산 Vm 은 Sm 과 같다.오차변동 Se 를 자유도로 나눈 값이 오차분산 Ve 이다.
Ve = Se / fe = 26.5 / 9 = 2.94
지금 계산한 분산이 무엇을 의미하는지를 알아보려면, 분산의 기대값을 생각해 보면 된다. 일반평균에 관해서는 변동도 분산도 같은 값이므로 기대값도 같아진다. 즉
E (Vm) = k m2 + σ2
오차분산의 기대값은 앞 절에서의 식 E (Se) = ( k - 1 ) σ2 을 자유도 (k - 1) 로 나누어
E (Ve) = ( k - 1 ) σ 2 / ( k - 1 ) = σ2 (※)
이므로 계산으로 구한 오차분산은 무한 회의 y의 분산, σ2 을 추정하는 결과가 된다.
따라서 일반평균의 순변동 Sm' 는 다음과 같이 추정할 수 있다.
즉,식 E (Sm) = Sm' + σ2 에서 E (Sm)에 실제 Sm 을 사용하여
Sm' ( = k m2 ) = Sm - σ2 = Sm - Ve = 202.5 - 2.94 = 199.56
오차의 순변동은
Se' = Se + σ2 = Se + Ve = 26.5 + 2.94 = 29.44
가 된다.
전변동에서 차지하는 순변동의 비율을 기여율이라고 하며,ρ(rho)로 표기한다.
ρm = Sm' / ST × 100 = 199.56 / 229.0 × 100 = 87.1 (%)
ρe = Se' / ST × 100 = 29.44 / 229.0 × 100 = 12.9 (%)
기여율에 대해서도
ρm + ρe = 100 (%)
가 성립된다.
이상의 내용을 보기 쉽도록 분산분석표로 정리하는 수가 많다.

분산 (V) 의 난은 변동 (S) 을 자유도 (f) 로 나누어 구한 것이다.그리고 전체 T의 분산은 제시하지 않는 경우도 많지만, 제시하는 경우에는 변동을 자유도로 나눈 것이어야 한다. 분산의 난은 합계해서는 안된다는 사실에 주의해야 한다.순변동,기여율은 앞 절에서 설명한 바와같다. 그리고 기대값의 난은 통상 생략하지만, 제시할 경우에는 분산분석표의 오른쪽 끝에 표시한다.
분산의 기대값은
E (Vm) = k m2 + σ2
E (Ve) = σ2
이었다. 따라서 치우침 m 이 없거나 아주 작은 경우에는 Vm 과 Ve 는 같은 정도가 될 것이다.여기서는 Ve 에 비해 Vm 은 100배 정도가 되므로 치우침이 없다고는 할 수 없을 것이다.
만약 Vm 이 Ve 정도( Vm 이 Ve 보다 작은 경우도 있다)라면, 치우침(m)은 인정할 수 없으며 치우침을 수정하는 의미도 없다. 이같은 경우에는 오차(개체차)와 치우침을 구별할 필요는 없고 Sm 은 오차와 같은 종류로 보아 합치는데 이를 오차에 풀(pool)한다고 한다. pool한 다음의 오차분산은 일반적으로 V(e) 로 표시하며 다음과 같이 구한다.
V(e)=( 오차변동 Se + pool할 인자변동 ) / ( fe + pool할 인자 자유도 )
일반평균과 오차변동밖에 없는 경우에 일반평균을 pool하면, pool한 다음의 오차분산 V(e) 은 총분산 VT 그 자체가 된다.
일상 제조등에서는 치우침이 있더라도 비교적 작다. 이같은 경우에 치우침을 수정하면 수정후의 산포는 ( y - y )2 의 평균이 된다.따라서 이상과 같은 제곱합의 분해를 함으로써 치우침을 수정하지 않았을 경우의 분산 ( VT )과 수정하는 경우의 분산 ( Ve )이 구해진다.
치우침을 수정하지 않으면, 목표값으로부터의 차이의 제곱 평균은
VT = ( 52 + 52 + … + 62 ) / 10 = 229 / 10 = 22.9
이므로,망소특성의 손실함수는
L = A0 /Δ02 × σ2
= 300 / 52 × 22.9 = 12 × 22.9 = 274.8 (원 / 개)
이다.
( 단, A0 :트러블이 발생할 때의 손실( 300원 ), Δ0 :트러블이 발생하는 한계값( 5 ㎛ ). 이 값들은 2.2절의 처음에 제시한 값이다.)
이 例에서는 제곱합의 분해로부터 치우침(m)을 무시할 수 없다는 사실을 알았다. 치우침이란 대부분의 경우 기술적으로 수정이 가능하다.
치우침을 수정하면 산포는 Se 를 자유도로 나눈 오차분산 Ve 이며 손실함수의 값은
L = 300 / 52 × 2.94 = 35.3 (원 / 개)
이 된다.치우침을 수정하므로 물품 1개당 239.5원의 품질향상이 가능하다.
치우침을 구하는 방법과 치우침의 수정에 의한 품질향상을 평가했는데,품질공학에서는 대부분 제어인자 가운데서 치우침을 수정한 다음의 산포가 작아지는 조합을 찾는 경우가 많다. 이때 SN비가 효과적인 특성값이 된다. 목표값이 있는 경우(망목특성)의 SN비에 대해서는 치우침을 수정할 수 없는 경우와 수정할 수 있는 경우를 생각해야 한다.
지금 어떤 목표값 y0 에 대해 y1, y2, …, yk 가 얻어졌다고 하자. 만약 평균이 목표값에 대해 치우칠 때 그것을 수정할 수 없다면 제곱합의 분해는 해도 쓸모가 없는 것이다.
(yi - y0 )2 의 평균을 VT 로 하면 손실함수 L은
L = k ( yi - y0 )2 의 평균 = k VT
가 된다. 따라서 SN비 η는
η = - 10 log VT
로 주어진다. 2.6절의 경우 VT = 22.9 이므로
η = - 10 log VT = - 13.6 (dB)
다음에 치우침을 수정하는 조정인자로 평균값 (m)을 목표값 (y0)에 맞추기로 한다.이 때 수정 후의 값은
y i' = y i × y0 / m
y i' = y i + ( y0 - m )
의 두종류가 있을 수 있다 (어떤 값을 곱한 경우와 더한 경우)
단, m 은 평균 y 의 참값이지만, 실제로는 y 를 사용한다.
양자의 차이는 수정방법에 따른다. 즉, 출력의 형태(감도)를 바꿈으로써 조정하면 전자와 같이 되며,절삭기구의 위치를 변경하는 등으로 수정할 경우에는 후자가 될 것이다 ( y = ax + b 에서 기울기 a 를 조정하는 경우가 前者. 절편 b 를 조정해서 평행 이동하는 경우가 後者의 예 ). 어느 경우이든 치우침은 없어진다.그러나 수정후의 yi' 의 산포는 달라진다.
전자의 식에 대한 SN비는 다음 절에서 설명한다.
후자의 식에서, 수정 전의 ( yi - y )의 제곱평균을 σ2 으로 하면, 수정후의 ( yi' - y' )의 제곱 평균 σ'2 도 σ2 이다. 따라서 수정후의 손실함수 L2는
L2 = k σ'2 = k ( yi - y )의 제곱평균 σ2
으로 주어진다.이 경우의 SN비는 σ2 의 역수로서 데시벨단위의 SN비는
η = -10 log σ2
이다. 제곱합을 치우침 m 과 개체차 e 로 나누었을 때의 오차분산 Ve 의 추정값은 σ2 이었으므로 실제 계산에서는
η = -10 log Ve
로 하면 된다.
앞 절의 사례에서는 분산분석표에서 Ve = 2.94 이므로
η = - 10 log Ve = - 4.7 (dB)
위의 2개 식중 패러미터 설계등에서 전자가 더 일반적이다. 다만, 목표값 y0 와 평균이 몇 퍼센트 정도밖에 다르지 않다면 전자의 경우도 후자와 같이 다룰 수 있다.
2.6절까지는 목표값 y0로부터의 차이를 데이터로 해 왔다. 그런데 대폭적인 수정이거나 혹은 출력방식의 조정이라는 방법으로 치우침을 수정할 경우, 조정후의 산포는 앞절의 前者의 식을 이용한
σ2 ’ = σ2 × ( y0 / m )2 = y02 × ( σ2 / m2 )
으로 된다.
|
분산 (V) 의 성질로서 다음의 정리가 있다. |
|
X가 확율변수이고 a가 상수일 때 V (aX) = a2 V (X) 그런데 앞 절에서의 식 y i' = y i × y0 / m 에서 수정을 위한 값 ( y0 / m ) 는 상수이다. y i 의 분산이 σ2 이고, y i' 의 분산을 σ2 ’ 라 하면 위의 정리에 의해 σ2 ’ = ( y0 / m )2 × σ2 |
위 식의 m2, σ2 을 실제 데이터로부터 추정하려면 목표값을 빼기전의 데이터를 사용하여, 그 제곱합 ST를, 평균 변동 Sm과 평균으로부터의 변동 Se로 분해한다. 이 계산순서는 앞에서와 같다.
2.2절의 데이터를 목표값 100을 빼기 전의 두께 데이터로 나타낸다.
105, 105, 102, 104, 103, 108, 105, 104, 103, 106
이에 대해 제곱합의 분해를 적용한다.
ST = 1052 + 1052 + … + 1062 = 109229 (f = 10)
Sm = ( 105 + 105 + … + 106 )2 / 10 = 10452 / 10 = 109202.5 (f = 1)
Se = ST - Sm = 26.5 (f = 9)
분산분석표로 정리하면 다음과 같다.
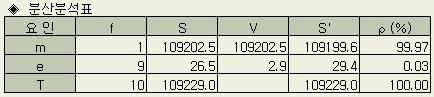
단, 순변동 Sm' (참된 평균 m의 제곱의 10배)는 다음과 같이 추정했다.
Sm' = Sm - Ve = 109202.5 - 2.9 = 109199.6
그리고 오차변동 Se 의 순변동은
Se' = Se + Ve
= 26.5 + 2.9 = 29.4
같은 m 이라는 기호일지라도 문제에 따라서 치우침의 변동이 되거나 단순한 평균값의 변동 (평균제곱의 n배) 이 되거나 하는데, 계산대상이 된 데이터가 무엇인가에 따라서 달라지게 된다. 그러나 e 는 어느 쪽이나 마찬가지가 된다.
한편, 이 절의 문제는 수정후의 산포가 σ2 ’ = y02 × (σ2 / m2 ) 와 같이 되는 경우에 조정후의 산포, 또는 그 역수인 SN비를 평가하는 것이다. 이를 위해서는 식의 참된 평균 m의 제곱이나 참된 개체차 σ2 을 평가할 필요성이 있다
일반평균 Sm의 기대값이
E (Sm) = k m2 + σ2
E (Ve) = σ2
이었으므로 m2 은
m2 = ( Sm - Ve ) / k
로 추정할 수 있다. 따라서 데시벨 단위의 SN비는
η = 10 log ( m2 / σ2 )
= 10 log [ { ( Sm - Ve ) / k } / Ve ] (※)
할 수 있다 .
실제로 구해 보면
η = 10 log [ { ( 109202.5 - 2.9 ) / 10 } / 2.9 ] = 35.70 (dB)
이와 같이 구한 SN비를 개선하는 것은 치우침을 수정한 다음의 품질을 개선하는 결과가 된다. 지금 평균값을 목표값 100으로 조정했을 때 조정후의 산포 σ2'는
σ2' = y02 / η의 眞수(비변환값) = 1002 / 3706.8 = 2.69
가 된다. 이 경우에는 치우침이 수 퍼센트이기 때문에 조정후의 데이터가 2.7절의 중간부 두가지 식에서 조정후의 산포 σ2 ’ 를 어느쪽으로 구해도 큰 차이는 없다.
여기서는 특정한 조건의 SN비를 구했지만, 직교표에 의한 실험의 경우, 내측 조건별로 이같은 SN비를 구하고, 그 데시벨값에 대한 내측 해석을 하여 SN비를 개선하는 인자를 발견하게 된다.
그리고 SN비의 분자를 감도 (S)라고 한다.
S = 10 log m2
= 10 log { ( Sm - Ve ) / k } (※)
감도 (S)는 평균값에 효과가 있는 인자를 찾고, 또한 목표치로 조정하는 경우에 사용된다 .
1) 조정후의 오차
망목특성에 있어서 산포는 목표값과의 차이를 조정한 다음의 값을 평가하는 것이 원칙이다. 앞 절까지는 반복등으로 얻은 데이터를 대상으로 했지만, 배치(batch)나 날짜를 바꾸어 데이터를 취하는 경우가 있다. 목표값과의 차이를 배치별로, 또는 날짜별로 조정하는 경우는 많다. 이 경우의 배치간의 차이나 날짜별로 발생하는 차이는 조정후의 오차가 아니다.
어떤 철판 두께의 목표값은 760㎛ 이다. 생산된 3개의 코일 A1, A2, A3 각각에 대해 폭 및 길이 방향 6개소의 두께를 계측하고 목표값과의 차이를 구한 데이터는 다음표와 같다.
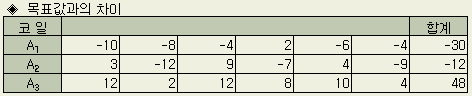
이와 같이 코일이라는 특정한 하나의 인자에 대한 데이터가 주어질 때 일원(一元)배치라고 한다. 세가지에 대한 데이터라면 3수준이라고 한다.
전체의 치우침은
y = ( -30 - 12 + 48) / 18 = 0.333
이므로 전체적 치우침은 미미한 것 같지만, 코일별로 분석해 보면 실제로는
A1 = -30 / 6 = - 5
A2 = -12 / 6 = - 2
A3 = 48 / 6 = 8
과 같이 치우침에 차이가 있다.
코일 i의 j번째 두께와 목표값과의 차이 yij 는
yij = y + ( A i - y ) + ( yij - A i ) (2. a)
로 나타낼 수 있다. 전체의 치우침 밖에 생각하지 않은 경우에는
yij = y + ( yij - y )
이며, 전제곱합 ST 와 치우침의 크기 Sm 의 차이에는 코일간의 차이가 들어가게 된다. 코일별로 조정하면 이 차이는 없어지므로 조정후에 오차의 크기로서는 앞에서의 식중에서 ( yij - A i )의 제곱합을 생각하는 것이 타당하다. 이에대해 생각해 보자.
2 ) 제곱합의 분해와 분산분석
우선 제곱합 ST 전체의 치우침 Sm 을 구한다.
ST = (-10 )2 + (-8 )2 + … + 42 = 1088 (f = 18)
Sm = ( -30 - 12 + 48 )2 / 18 = 62 / 18 = 2 (f = 1)
다음에 식 (2. a)의 우변 제2항 (AI - y )의 제곱합은 A 에 의한 변동 SA 라고 하며
SA = 6 ×[ ( A1- y )2 + ( A2 - y )2 + ( A3 - y )2 ] (2.b)
로 구할 수 있다. AI - y 는 6개씩 있으므로 [ ]의 6배로 되어 있다.
이를 정리하면 다음과 같이 고쳐진다.
SA = { ( A12 + A22 + A32 ) / Ai 의 반복수 6 } - Sm (f = 2)
자유도는 식 (2. b)에서 ( A1- y ) + ( A2 - y ) + ( A3 - y ) = 0 이므로 미지수는 2 이다. 따라서 f = 2 이다. k수준의 변동의 자유도는 ( k - 1 ) 로 기억하자.
실제로 계산해 보면
SA = { (- 30)2 + (- 12)2 + 482 } / 6 - 2 = 556 (f = 2)
다음에 코일간의 차이를 제외한 오차변동은 식 (2. a)의 우변 제3항의 제곱합이다. 이를 Se 로 표시한다.
Se = ( y11 - A1 )2 + ( y12 - A1 )2 + … + ( y16 - A1 )2
+ ( y21 - A2 )2 + ( y22 - A2 )2 + … + ( y26 - A2 )2
+ ( y31 - A3 )2 + ( y32 - A3 )2 + … + ( y36 - A3 )2 (2. c)
중간과정은 생략하지만, 최종적으로는
Se = ST - Sm - SA (f = 15)
가 된다. 자유도는 식 (2. c)의 18개항 가운데
( y11 - A1 ) + ( y12 - A1 ) + … + ( y16 - A1 ) = 0
( y21 - A2 ) + ( y22 - A2 ) + … + ( y26 - A2 ) = 0
( y31 - A3 ) + ( y32 - A3 ) + … + ( y36 - A3 ) = 0
이라는 제약이 있으므로 실질적인 미지수는 18 - 3 = 15 이며 f = 15 가 되지만, 전제곱합의 자유도 18 로부터 치우침의 자유도 1, A의 자유도 2 를 빼서 15 로 하면된다. 계산하면
Se = ST - Sm - SA = 1088 - 2 - 556 = 530 (f = 15)
이상에서 분산분석표는 다음과 같다.
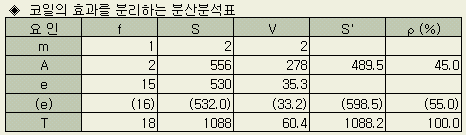
전체의 치우침 m은 오차분산보다 작으므로 pool했다. 그리고 SA 의 기대값 E[SA]는
E[SA] = SA' + A의 자유도 × 참된 오차분산 σ2
분산의 기대값 E[VA ]는
E[VA] = A의 반복수 × σA2 + 참된 오차분산 σ2
단, σA2 = (SA' / A의 반복수) / A의 자유도
이다.
따라서 A의 순변동 SA'는
SA' = SA - A의 자유도 × Ve (※)
= 556 - 2 × 33.2 = 489.5
오차의 순변동은
Se' = Se + A의 자유도 × Ve (※)
= 532 + 2 × 33.2 = 598.5
단, Se 에는 pool한 값을 사용했다.
이상에서 코일별로 목표값과의 차이를 조정하면, 산포는 33.2가 된다는 사실을 알 수 있다.
3) SN 비의 산출
조정후의 오차가 평균값에 비례하여 변화하는 경우의 SN비
η = 10 log ( m2 / σ2 )
= 10 log [ { ( Sm - Ve ) / k } / Ve ]
를 구할 경우에는 목표값으로부터의 차이가 아닌, 두께의 데이터로부터 평균값의 크기 Sm 을 구해야 한다.
Sm = ( 18 × 760 + 6 )2 / 18 = 10,405,922 (f = 1)
Ve 는 위의 분산분석표에서 m을 pool하기 전에 오차분산을 사용하여
η = 10 log [ { (10,405,922 - 35.3 ) / 6 } / 35.3 ] = 46.91 (dB)
로 한다. 이것은 코일별로 조정했을 때의 SN비이다.