
|
СІ4Цэ ЛчЗЪ 1Рх ИСМвЦЏМК |
|
1.2
SNКёРЧ
АшЛъ 1.5 УжРћСЖАЧ |
РЬРхПЁМДТ
СЄЦЏМКРЮ ИСМвЦЏМКРЧ ЛчЗЪЗЮ МГИэЧбДй (ИСДыЦЏМКРК SNКё, МеНЧЧдМіИІ БИЧЯДТ НФИИ
ДйИІ Лг ЧиМЎРЧ ЙцЙ§РК ИСМвЦЏМКАњ ЖШ ААДй).
КЙЛчПЁМРЧ
ЙйХСПРПАРЛ АГМБЧЯБт РЇЧи,
ДйРНАњ ААРК СІОю РЮРкИІ УЄХУЧЯАэ НЧЧшРЛ ЧбДйЃЎПРПАРЧ ЙЎСІРЬЙЧЗЮ ИСМвЦЏМКРЬДй.
(АЂ РЮРкРЧ СІ2МіСиРЬ ЧіЧр СЖАЧРЬДй)
ШЅЧеАш СїБГЧЅ L18ПЁМ 2МіСи РЮРкДТ СІ1ППЁ ЙшФЁЧиОп ЧЯИч, 3МіСиРЧ РЮРкДТ СІ2~8ПРЧ ОюДР ППЁ ЙшФЁЧиЕЕ ССДй. НЧЧшРЮРкАЁ 6АГРЬЙЧЗЮ ГВАдЕЧДТ ЕЮП (ОюЖВ ПРЛ КёПіЕЕ ЙЋЙцЧЯИч, ПЉБтМДТ СІ7, 8ПРЛ КѓПЗЮ ЧЯПДДй)РК РкЕПРћРИЗЮ ПРТїПЗЮ УГИЎЕШДй.
СїБГЧЅРЧ ПмУјПЁ ЧвДчЕЧДТ ПРТї РЮРкДТ НЧЧшЗЎРЛ СйРЬБт РЇЧи plusУјСЖАЧ, (ЧЅСиСЖАЧ), minusУјСЖАЧРЬЖѓДТ 2~3МіСиРИЗЮ СЖЧеЧв Мі РжДй. ПЉБтМДТ ПЕЧтЗТРЬ ГєРК ПТ НРЕЕРЧ СЖЧеРИЗЮ 3МіСиРИЗЮ ЧбДй.
ёЩ : plus, minusЖѕ ЦЏМКФЁАЁ РлОЦСіАэ ФПСіДТ ЙцЧтРЛ РЧЙЬЧЯИч, ССДй ГЊЛкДйПЭДТ КААГДй.
ЙйХСПРПАРК ЃАСЁРЬ ИИСЁ (ЙйХСПРПА ОјРН)РИЗЮНс 10 ДмАш (ЃАЁ9) ЗЮ ЦђАЁЧбДй. СїБГЧЅПЁРЧ ЧвДчАњ УјСЄФЁДТ ОЦЗЁПЭ ААДй.
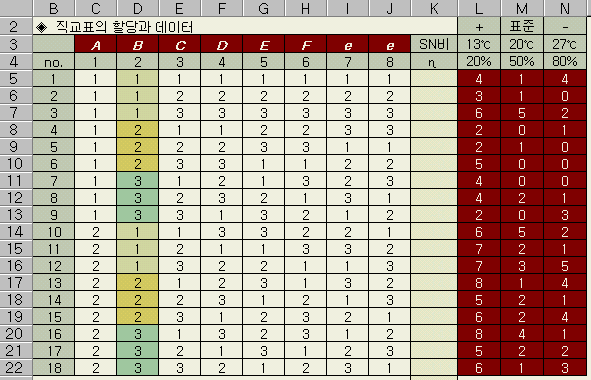
(Ёи ДйИЅ ЛчЗЪПЁМЕЕ ИЖТљАЁСіЗЮ, ExcelРЧ И№Еч sheet ПЁМ КгРК ЙйХСМПИИ РдЗТРЬ ЧЪПфЧб КЮКаРЬИч, ГЊИгСіДТ И№ЕЮ АшЛъНФРИЗЮ РкЕПАшЛъЕЧДТ КЮКаРЬДй.)
ЂТ
SNКё (ИСМвЦЏМК)
Ѕч = -10 × log { (
ЂВyi2 ) / n }
no.1РЧ
ПЙ
Ѕч1 = -10 × log { ( 42
+ 12 + 42 ) / 3 } = -10.4
K5РЧ
Excel НФ = -10 *LOG
( SUMSQ ( L5:N5 ) / 3 )
no.
2 ~ 18 РЧ АшЛъРК РЇРЧ НФРЛ РдЗТЧб K5 МПРЛ K6:K22 МППЁ КЙЛчЧЯИщ ЕШДй.
|
Ёи
УжРћСЖАЧРЛ ДйЗчДТ НЧЧшПЁМ УыБоЧЯДТ ЦЏМКРК ПЉЗЏ АГАЁ РжРЛ Мі РжАэ,
Бз ЦЏМКПЁ ЕћЖѓ Ёи
ИСДыЦЏМКРЧ
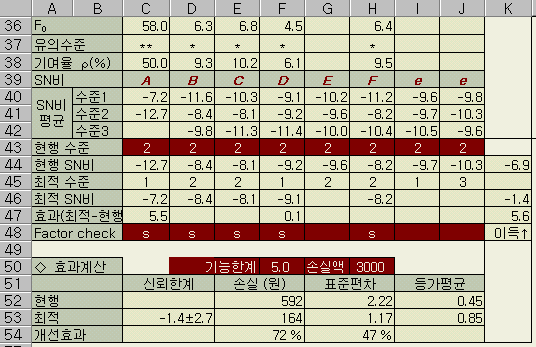
АцПьЖѓИщ SNКёДТ ДйРН НФАњ ААДй. |
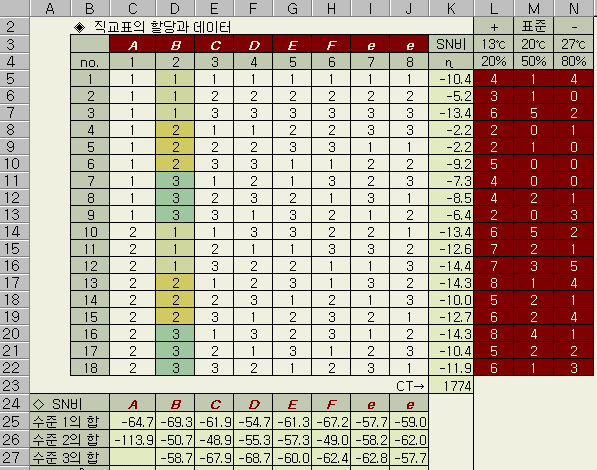
АЂ РЮРкКА КЏЕП АшЛъРК ДйРНАњ ААДй (ОЦЗЁПЁМ РЮРк B РЧ АшЛъ чгИІ ЕщАэ РжДй)
ЂТ
МіСи1РЧ Че
= (-10.4) + (-5.2) + (-13.4) + (-13.4) + (-12.6) + (-14.4) = -69.3
МіСи3РЧ
Че
= (-7.3) + (-8.5) + (-6.4) + (-14.3) + (-10.4) + (-11.9) = -58.7
Excel
НФ
МіСи1РЧ Че (D25)
=
SUMIF(D$5:D$22, 1, $K$5:$K$22) = -69.3
МіСи2РЧ
Че (D26) =
SUMIF(D$5:D$22, 2, $K$5:$K$22) = -50.7
МіСи3РЧ
Че (D27)
=
SUMIF(D$5:D$22, 3, $K$5:$K$22) = -58.7
Ёи 2МіСи ЙшФЁППЁМ 28~29ЧрРЧ n = 9, 32ЧрРЧ РкРЏЕЕ(f) = 1ПЁ СжРЧЧв АЭ (L18СїБГЧЅПЁМ 3МіСиРЧ ПРК ОюДР ЧбПРЛ АшЛъЧб ШФ ДйИЅ ППЁ КЙЛчЧЯИщ ЕЧГЊ, 2МіСиПРК КЙЛчЧиМ ОШЕЧАэ ЦВИЎБт НБДй)
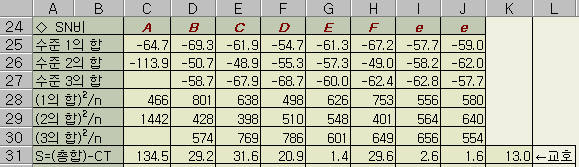
ЂТ
КЏЕП (S)
SB
= { ( -69.3 )2 / 6 + ( -50.7 )2 / 6 + ( -58.7 )2
/ 6 } -CT
= { ( -69.3 )2 + ( -50.7 )2 + (-58.7)2 } /
6 -CT
= 29.2
Дм,
МіСЄЧз
CT = {
( -10.4 + (-5.2) + (-13.4) + + (-11.9) }2
/ 18 = 1774
( Excel
НФ K23
= SUM (K5:K22)^2 /
18 = 1774 )
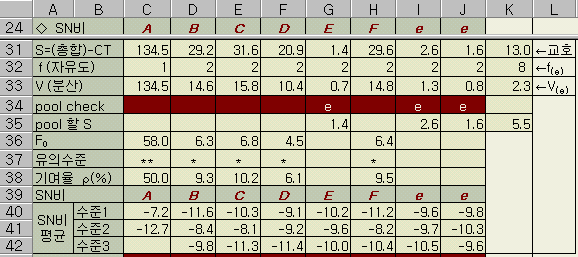
ЂТ
КаЛъ (V)
VB
= КЏЕП / РкРЏЕЕ = SB / fB
= 29.2 / 2 = 14.6
ЂТ
ПРТїРЧ pooling
33ЧрПЁ
ГЊХИГЊДТ КаЛъ (V)РЬ РлДйДТ АЭРК SNКёПЁ ПЕЧтРЬ ОјДТ РЮРкЗЮ КМ Мі РжДйДТ ЖцРЬИч,
ПРТїЗЮ КИОЦ ЙЋЙцЧЯДй. РЬЗБ РЮРкАЁ ПРТїПЁ ЧеУФСіИщ(pooling),
ПРТїРкУМРЧ НХЗкЕЕАЁ ГєОЦСіАэ, РЬЗЮНс РЮРкРЧ АЫУтЗТРЬ ГєОЦСјДй. РЬ НЧЧшПЁМ
poolingРЧ
ДыЛѓРК {ПРТїП(РЮРкАЁ ЙшФЁЕЧСі
ОЪРК П) + 33ЧрРЧ VАЊРЬ РлРК РЮРк + 1, 2ПРЧ БГШЃРлПы(L18РЯ ЖЇИИ)}
ЕщРЬИч, V(e)
= (poolingЧЯДТ РЮРкРЧ КЏЕП Че / poolingЧЯДТ РЮРкРЧ РкРЏЕЕ Че)
И№Еч
ППЁ РЮРкАЁ ЙшФЁЕЧОю ПРТїПРЬ ОјРЛ АцПьПЁДТ VАЊРЬ РлРК Ию АГРЧ РЮРкИІ poolingЧЯПЉ
ПРТїКаЛъРИЗЮ ЧбДй. poolingЧб
КаЛъАњ РкРЏЕЕДТ УЗРк (e)ИІ КйПЉ БИКа ЧЅНУЧбДй.
КаЛъКё(Fo)ГЊ МјКЏЕП(S') БтПЉРВ(Ѕё)РК poolingЧб ПРТї Ся V(e)ИІ БтСиРИЗЮ АшЛъЧбДй.
Ёи K31~K35РЧ 4 МПРК poolingЕШ ПРТїКаЛъ V(e)РЧ АшЛъАњ АќЗУЕЧДТ КЮКаРЬДй.
K31: 1ПАњ 2ПРЧ БГШЃРлПы КЏЕП
=
УбКЏЕП(ST) - 8АГ ПРЧ КЏЕП ЧеАш
=
DEVSQ(K5:K22) -SUM(C31:J31)
=
264.4 -251.4 = 13.0
K32
: pooling
ПРТїРЧ РкРЏЕЕ
=
( ЙшФЁЕШ ПРТї + poolingЧв
РЮРк + 1,2ПРЧ БГШЃРлПы )
=
4 + 2 + 2 = 8
K33 : pooling
ПРТїКаЛъ V(e)
= ( K35 + K31 ) / K32 = ( 5.5 + 13.0 ) / 8 = 2.3
C34~J34 : C33~J33РЧ КаЛъРЛ БтСиРИЗЮ poolingЧЯАэРк
ЧЯДТ РЮРкППЁ e РдЗТ
K35
:
poolingЧв
ПРТї КЏЕП( ЙшФЁЧб ПРТї + poolingЧв
РЮРк )
ЂТ
КаЛъКё (F0)
VB
/ V(e)
= 14.6 / 2.3 = 6.3
ЂТ
РЏРЧМК АЫСЄ
FКаЦїЧЅПЁМ
МіФЁИІ ШЎРЮЧЯПЉ РЇПЁМ АшЛъЧб F0 ПЭ
КёБГЧбДй.
КаРкРЧ РкРЏЕЕАЁ 2РЮ АцПь (B,
C, D, E, F, e, eРЧ 7ППЁ ЧиДч)
F
(fB,
f(e),
0.05) = F(2, 8, 0.05) = 4.46
F
(fB,
f(e),
0.01) = F(2, 8, 0.01) = 8.65
Дм,
2МіСиРЮ РЮРкA ППЁМДТ РкРЏЕЕ ( fA)АЁ
1РЮ АЭПЁ СжРЧ
F
(fA,
f(e),
0.05) = F(1, 8, 0.05) = 5.32
F
(fA,
f(e),
0.01) = F(1, 8, 0.01) = 11.26
36ЧрРЧ
F0
АЁ F0
> F (fB,
f(e),
0.05) = 4.46 РЬИщ
РЇЧшРВ 5%ЗЮ РЏРЧ (*ЧЅНУ)
107410 F0
> F (fB,
f(e),
0.01) = 8.65 РЬИщ РЇЧшРВ 1%ЗЮ РЏРЧ (**ЧЅНУ)
ЂТ
БтПЉРВ Ѕё(%)
ЅёB
=
( SB
- fB
× V(e)
) / ST × 100 = ( 29.2 - 2 × 2.3 ) / ST
× 100 = 9.3 (%)
Дм,
ST =
{
(-10.4)2
+ (-5.2)2
+ ЁІ
+ (-11.9)2
}
-CT
=
DEVSQ (K5:K22) =
264.4
ЂТ МіСи1 ЦђБе D40 = D25 / 6 = -69.3 / 6 = -11.6
ЧиМГ
(1)
L18
СїБГЧЅРЧ ЦЏРЬСЁ
ST
(УбКЏЕП) = (-10.4)2
+ (-5.2)2
+ ЁІ + (-11.9) 2
-CT(1774) = 264.4
ЧбЦэ
КЏЕПАшЛъЧЅРЧ АЂ РЮРкКА КЏЕП(S)РЧ
ЧеАш (C31:J31РЧ ЧеАш)ДТ 251.4РЬДй. РЬ ЕЮАЊРЧ ТїРЬ 264.4 -251.4 = 13.0 РК L18СїБГЧЅРЧ
ЦЏРЬСЁРИЗЮ СІ1ПАњ СІ2ПРЧ БГШЃРлПы(A × B)РЬДй. БГШЃРлПыРК ПРТїРЧ РЯКЮЗЮ
Л§АЂЧЯДТ АцПьЕЕ РжРИЙЧЗЮ ИХПь ХЋ АЊРЬ ОЦДв АцПьПЁДТ ПРТїЗЮ УыБоЧбДй.
БГШЃРлПыРЧ РкРЏЕЕДТ АЂ РЮРкРЧ РкРЏЕЕРЧ АіРЬДй. L18 СїБГЧЅРЧ УбРкРЏЕЕДТ 17РЮЕЅ, КЏЕПАшЛъЧЅПЁМ АЂ РЮРкРЧ РкРЏЕЕ ЧеАш(C32:J32РЧ ЧеАш)ДТ 15РЬДй. РЬ ТїРЬ (2 = 17 -15) АЁ БГШЃРлПыРИЗЮ МћАмСј РкРЏЕЕРЬИч, ПРТїЗЮ poolingЧв ЖЇДТ ЧеУФСЎОп ЧЯДТ АЭРЬДй. РЇ КаЛъКаМЎЧЅРЧ kПРЬ РЬЕщАњ АќЗУЧб МіФЁЕщРЬДй
(2) МјКЏЕПАњ БтПЉРВ
ХфГЪ(C)РЧ КЏЕПРК КаЛъКаМЎЧЅ E31ПЁМ 31.6 РЬДй. Ся SCДТ C(ХфГЪ)РЧ МіСиКЏШПЁ РЧЧи ЙпЛ§Чб ХЉБтРЮЕЅ, ААРК СЖАЧПЁМ ПЉЗЏ Йј УјСЄЧЯИщ ААРК АЊРЬ ОЦДЯЖѓ, ОюЖВ АЊРЛ СпНЩРИЗЮ КаЦїИІ РЬЗъ АЭРЬДй. РЬААРЬ СпНЩРћРЮ АЊРЛ БтДыАЊ(Expected value)РЬЖѓ ЧбДй. СіБн БИЧб CРЧ КЏЕП SCРЧ БтДыАЊРК ДйРНАњ ААРЬ ЕШДй.
E[SC]
= SCЁЏ
+ CРЧ РкРЏЕЕ × V(e)
РЬДй. Ся SCПЁДТ
(ЧиДчРЮРк РкРЏЕЕ × ПРТїКаЛъ)АЁ ЦїЧдЕЧОю РжДйДТ АЭРЬДй. БзЗЏЙЧЗЮ SCЁЏИІ
РЮРк CРЧ МјКЏЕП(ТќЕШ ШПАњ)РЬЖѓ ЧЯАэ Бз АЊРЛ УпСЄЧЯИщ
SCЁЏ
= SC
- ( CРЧ РкРЏЕЕ × V(e)
)
= 31.6 - ( 2 × 2.3 ) = 27.0
ЧбЦэ АЂ РЮРкРЧ МјКЏЕПРЛ БИЧв ЖЇ КќСј ПРТїКаЛъРК
ПРТїКЏЕП S(e)ПЁ
ЧУЗЏНКЧЯПЉ ПРТїРЧ МјКЏЕП S(e)ЁЏ
РЬ ЕШДй.
S(e)ЁЏ
= S(e)
+ (poolingПРТїПЁ
ЕщОюАЁСі ОЪРК РкРЏЕЕ ЧеАш × V(e)
= 18.5 + 9 × 2.3 = 39.2
ST
= SAЁЏ
+ SBЁЏ
+ SCЁЏ
+ SDЁЏ
+ SFЁЏ
+ S(e)ЁЏ
=
SA
+ SB
+ SC
+ SD
+ SF
+ S(e)
=
264.4
РќКЏЕП(ST)ПЁМ
ТїСіЧЯДТ МјКЏЕПРЧ КёРВРЬ БтПЉРВ Ѕё РЬДй.
ЅёC
= ( SCЁЏ
/ ST
) × 100 = 27.0 / 264.4 × 100
=
10.2 (%)
РЬ БтПЉРВРЧ РЧЙЬДТ 18АГ SNКёАЁ -14.4 dBПЁМ -2.2 dBРЧ ЙќРЇЗЮ ЛъЦї(K5 ~ K22) ЧЯДТЕЅМ 10.2%АЁ ХфГЪ(C)ПЁ РЧЧб ПЕЧтРЬЖѓДТ АЭРЬДй. ПРТїКаЛъКИДй РлРК ПфРЮРК БтПЉРВРЛ АшЛъЧЯСі ОЪДТДй.
ПфРЮ ШПАњЕЕ
( АшЛъЧЅРЧ 40~42ЧрПЁМ МіСиКА ШПАњИІ ЙйЗЮ ОЫ Мі РжРИЙЧЗЮ ПфРЮШПАњЕЕИІ ЙнЕхНУ БзИБ ЧЪПфДТ ОјДй.)
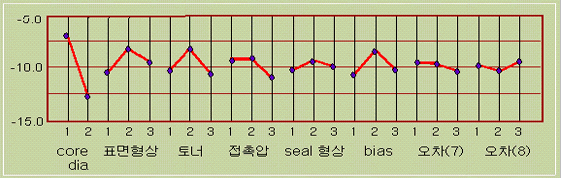
УжРћ СЖАЧРК SNКёРЧ УжДыРЧ СЖЧеРЬДйЃЎ РЬ ПЙСІПЁМ УжРћ СЖАЧРК A1 B2 C2 D1 E2 F2 ЗЮ ГЊХИГДй. И№Еч РЮРкРЧ УжРћМіСиРЧ СЖЧеРК АњДыУпСЄ АЊРЬ ЕЩ Мі РжБт ЖЇЙЎПЁ, УжРћ СЖАЧРЧ УпСЄПЁДТ РќУМ ПфРЮРЧ Ор ЙнМіЗЮ АшЛъЧбДйЃЎ(ЧіЧр СЖАЧРК И№ЕЮ СІ2МіСиРЬДй. УжРћСЖАЧПЁМРЧ РЬЕцРК core diaПЁМИИ ГЊХИГДй)
ПЉБтПЁМДТ, КаЛъ КаМЎЧЅЗЮКЮХЭ, ШПАњАЁ ХЋЃЕАГРЧ ПфРЮ A, B, C, D, FИІ МБХУЧЯАэ АшЛъЧбДй.
УпСЄРЧ
ИюАЁСі ЙцЙ§
Јч
Ор Р§ЙнРЧ ХЋ ПфРЮИИ АшЛъ
Јш
КаЛъКаМЎПЁМ КаЛъКёАЁ 2РЬЛѓРЮ АЭ
Јщ
КаЛъКаМЎРЧ FАЫСЄРИЗЮ РЏРЧЧб АЭ
Јъ
ЧвРЮАшМіЙ§
ЂТ
УжРћСЖАЧРК
РќУМЦђБеПЁМ АЂ РЮРкРЧ ШПАњИІ ЧеЧЯИщ ЕЧЙЧЗЮ
Ѕь = T + ( A1
-T ) + ( B2
-T ) + ( C2
-T ) + ( D1
-T ) + ( F2
-T )
= A1
+ B2
+
C2
+ D1
+
F2
-4 × T
= (-7.2)ЃЋ(-8.4)ЃЋ(-8.1)
ЃЋ(-9.1) ЃЋ(-8.2)ЃЃД(-9.9) = -1.4
ЂТ
УжРћСЖАЧПЁМРЧ НХЗкЧбАш(СпПфЧЯСіДТ
ОЪДй)
± Ёю{ F(1, Ѕѕe,
0.05) × Ve
× 1 / ne
}
ПЉБтМ, F(1, Ѕѕe,
0.05) = F(1, 8, 0.05) = 5.32
Ve
= 2.3
ne
= РќУМНЧЧшМі / ЅчРЧ УпСЄПЁ АэЗСЧб РкРЏЕЕРЧ Че(A, B, C, D, F, T)
= 18 / ( 1 + 2 + 2 + 2 + 2 + 1 ) = 18 / 10 = 1.8
neДТ
РЏШПЙнКЙМіЖѓАэ ЧЯИч ЅьАЁ
Ию АГРЧ ЦђБеПЁ ЧиДчЕЧДТСіИІ ГЊХИГНДй.
ЁХ
± Ёю { 5.32 × 2.30 × 1 / 1.8 } = 2.6
ЂТ
ЧіЧр
СЖАЧРЧ АјСЄ ЦђБе УпСЄЃЎ
Ѕь = T + ( A2
-T ) + ( B2
-T ) + ( C2
-T ) + ( D2
-T ) + ( F2
-T )
= A2
+ B2
+
C2
+ D2
+
F2
-4 × T
=(-12.7)ЃЋ(-8.4)ЃЋ(-8.1)
ЃЋ(-9.2)ЃЋ(-8.2)ЃЃД(-9.9) = -6.9
ЕћЖѓМ
УжРћ СЖАЧРЧ РЬЕц(gain)РК
УжРћФЁ
-ЧіЧрФЁ = (-1.4)Ѓ(-6.9)
= 5.5 (dB)
УжРћ СЖАЧРЬ АсСЄЕЧИщ, ЧіЧр СЖАЧАњ УжРћ СЖАЧЧЯПЁМ, РЇРЧ РЬЕцРЬ
РчЧіЧЯДТАЁИІ ШЎРЮ НЧЧшРЛ ЧбДйЃЎ
УпСЄФЁРЧ АшЛъПЁМДТ Ор
ЙнМіРЧ ПфРЮРЛ ЛчПыЧЯГЊ,
АјСЄПЁ
РћПыЧЯДТ СЖАЧРК,
КёПыПЁ АќАшАЁ ОјДТ Чб СІОюРЮРкРЧ ССРК МіСиРЛ
И№ЕЮ
УЄХУЧбДйЃЎ
ЂТ
МеНЧБнОзРЧ АшЛъ
ЙйХСПРПАРЧ СЁМіАЁ 5ИІ ГбРИИщ(БтДЩЧбАш) МеНЧОзРЬ
3000ПјРЬДй.
ИСМвЦЏМКРЧ МеНЧЧдМіДТ
L
= ( A / ЅФ2
) × Ѕђ2
= ( A / ЅФ2
) × 10 (-Ѕч / 10)
(Ёё
Ѕч = -10 log Ѕђ2
ПЁМ Ѕђ2
= 10 (-Ѕч / 10) )
ЕћЖѓМ
L(ЧіЧр)
= 3000 / 5ЃВ
× 10 (6.9 / 10) = 592 (Пј)
L(УжРћ)
= 3000 / 5ЃВ
× 10 (1.4 / 10) = 164 (Пј)
БзЗЏЙЧЗЮ
АГДч МеНЧРЧ АЈМвДТ 592 - 164 = 428 (Пј),
(
592 - 164 ) / 592 × 100 = 72 % Ся МеНЧРЧ 72%ИІ СйРЬАд ЕШДй.
|
дѕЪЄ ЦђБе(ЛъЦїАЁ ОјДйАэ Чв ЖЇРЧ ЦЏМКФЁ)ПЁ РЧЧб ШПАњ УпСЄ |
|
ИСМвЦЏМКРЧ
SNКё Ѓ10
log {(y1ЃВ
+ y2ЃВ
+ ЁІ + ynЃВ
)ЃЏn}=Ѕч (dB)
y=Ёю 10 (-Ѕч / 10) y(УжРћ)=Ёю 10 (-Ѕч / 10) = Ёю 10 0.136 = 1.17 y(ЧіЧр)=Ёю 10 0.693 = 2.22 Ся ЙйХСПРПАРЬ 2.22СЁРИЗЮКЮХЭ 1.17СЁРИЗЮ ЧтЛѓЧб АЭРЬ ЕШДйЃЎ(ЕюАЁЦђБеРЧ Р§ДыФЁДТ, УЄХУЧб НЧЧшРЧ СЖАЧ(ПЉЗЏ NoiseРЧ СЖЧе)ПЁ ЕћЖѓ ДоЖѓСіЙЧЗЮ, РчЧіМКРК РЬЕцРИЗЮ УНХЉЧбДй) |